Notion is a great tool for writing but the content is trapped inside the web app.
The company is working on an official API but I’m impatient.
This article describes how I reverse engineered their API and created a Go library
notionapi.
It all began with a failure.
My first attempt at extracting notion content was traditional web scraping.
I found a Python
script that uses Selenium to recursively spider a Notion page and publish it to Firebase Hosting.
I ported it to Node to use
Puppeteer (better technology than Selenium).
While it worked this approach is limited to getting a verbatim HTML of the pages as they are rendered by the Notion application.
I wanted to be able to change the look of the page, add elements like footers and headers and navigation bar.
I briefly considered trying to reconstruct the structure of the page from rendered HTML but at best that would be a lot of ugly guesswork.
The lightbulb moment
Modern Single Page Applications (SPA) work by getting data from the server in structured format (most often JSON) and rendering HTML in the browser with JavaScript.
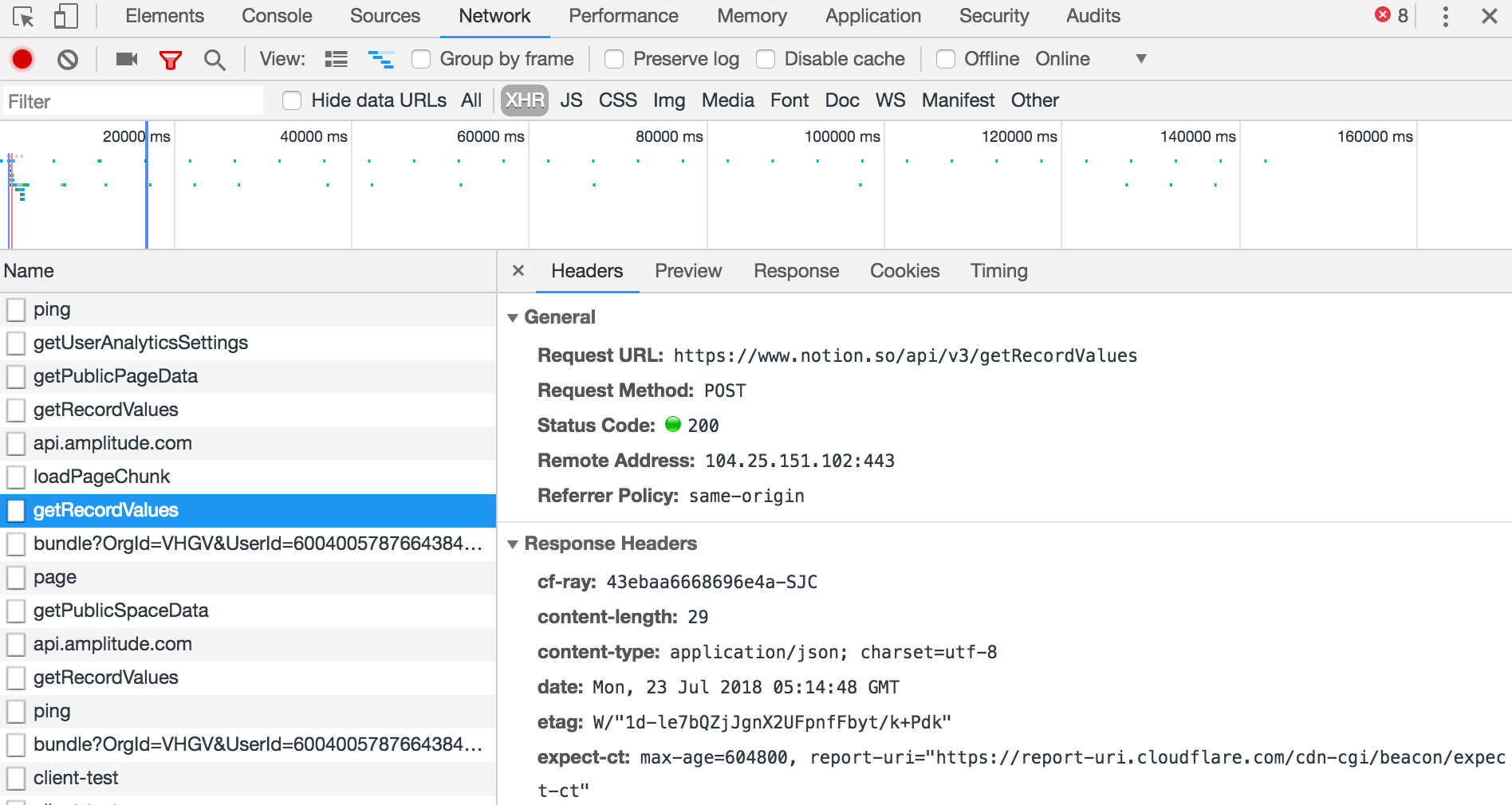
A trip to Chrome Dev Tools confirmed that Notion works like that.
When loading a Notion page I saw XHR requests like /api/v3/getRecordValues and /api/v3/loadPageChunk.
Lucky for me the API is not obfuscated. It returns responses as JSON data. It isn’t hard to figure out the meaning of fields.
Working with the original JSON structure is much easier that trying to reconstruct it from rendered HTML.
I could have looked at API requests between client and server in Chrome dev tools but it’s not the best workflow.
Instead I wrote node.js script that logs all XHR requests that web browser makes when rendering a given page.
That has several advantages over using dev tools:
- I could filter out requests to third-party services like amplitude, fullstory and intercom
- I could filter out requests that are not interesting like
/api/v3/ping
- I could pretty-print JSON
- I could write captured traffic to a file for further analysis
Here’s the script:
The big picture analysis
After looking at captured data, the structure of Notion content is not complicated.
Everything, including a top-level page, is a block.
Blocks are identified by a unique id which looks like a standard UUID format.
Blocks are arranged into a tree i.e. some blocks have children.
Blocks have metadata, like creation time, last edit time, version etc.
There are different kinds of blocks: a page, text, todo item, list item etc.
Some blocks have properties specific to that block type. For example a page block has title property.
To get the content of a page we start with its UUID which we can find out because it’s last part of the URL of the page.
We can issue /api/v3/getRecordValues API to get list of blocks in the page and then /api/v3/loadPageChunk to get content of those blocks.
Majority of work was figuring out what kinds of blocks there are, how are they represented in JSON and writing code to to retrieve the data and present it in a format that is easier to work with than the raw data returned by the server.
Testing different kinds of blocks
Notion page consist of different kinds of blocks and we need to know how each block is represented in JSON response.
To investigate it systematically, I’ve created a test page for each kind of block and used the request logging script to look at JSON returned by the server for that block.
Writing Go library
Next step was writing a Go library.
I captured sample JSON responses from
getRecordValues and
loadPageChunk and used
Quicktype to generate Go structures.
I had to tweak them a bit to accommodate variations in JSON structure.
The rest of the effort was writing a helper function that abstracts the details of HTTP requests and returns an easy to use struct describing a notion page.
There result of that work is
notionapi Go package.
Using the library in practice
This was not just an academic exercise.
This blog was powered by markdown files I stored in GitHub repository.
My goal was to move the content to Notion, so that I can edit it more easily, convert it to HTML and publish as my website/blog.
You can see the code
here.
The high-level structure of the code:
- I use my Go notionapi library to download the content from Notion
- I cache downloaded data and store them in git repository. This is to make sure I have a copy of data even if Notion disappears, to make it faster to tweak publishing code (no need to re-download) and to be nicer to Notion server (no re-downloads unless I absolutely have to)
- I convert Notion data to HTML, wrap it in templates for my pages and write HTML files to disk
- I deploy to Netlify